ChatGPT and aligning language models

ChatGPT changed the way we think about artificial intelligence. It's one of the tools that uncover the true potential of AI for all groups of users. But what made ChatGPT so powerful? ChatGPT is an agent simulated by the language model GPT-3.5. And in this article, I want to discuss a few fundamental things that made GPT-3.5 so effective.
Model scale & model alignment
GPT (Generative Pre-trained Transformer) is a large language model that uses deep learning to produce human-like text. The number of parameters defines the model scale. GPT-3 is called "large-scale" because it has 175 billion parameters.
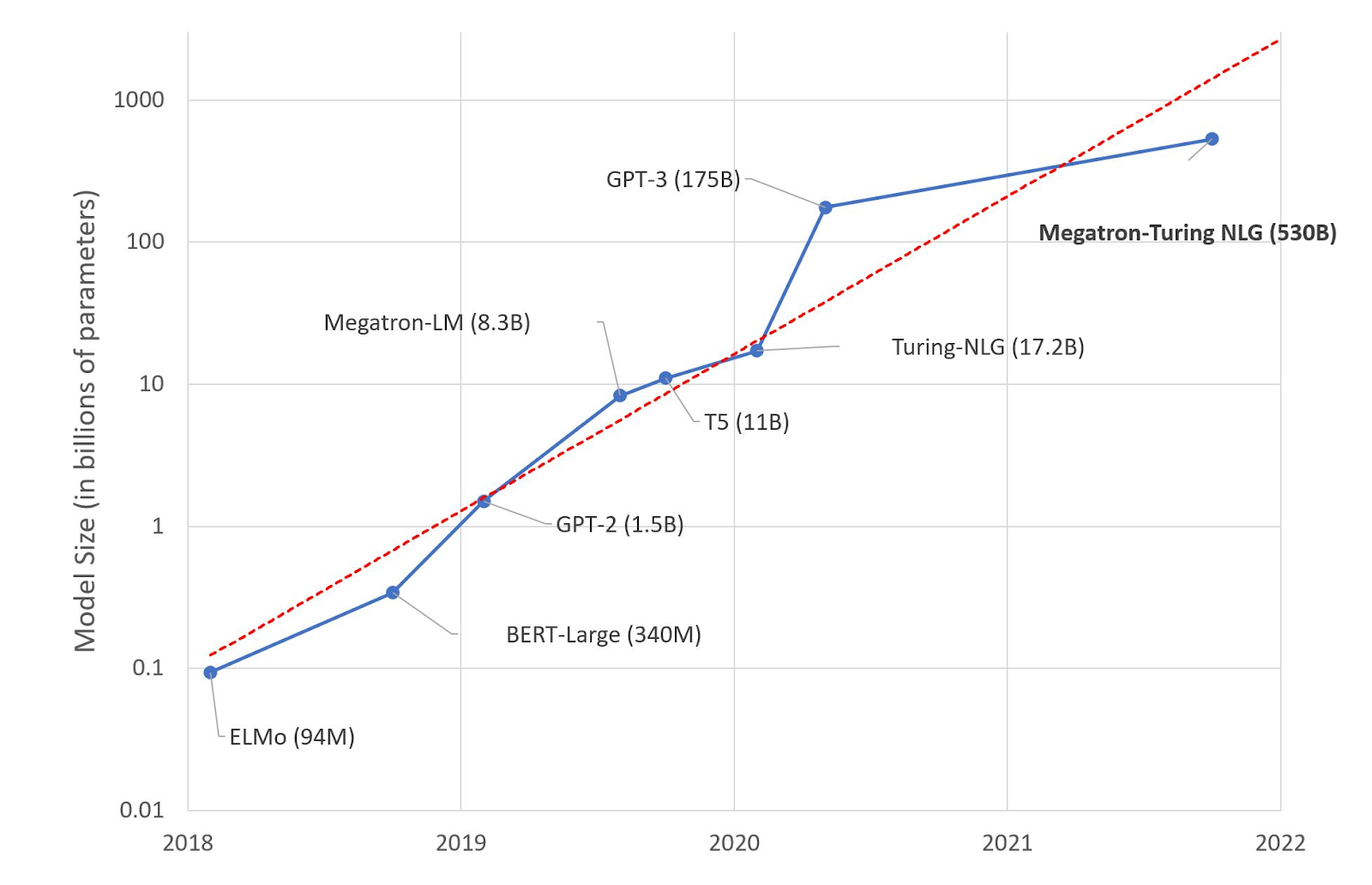
But not only does the number of parameters matter, but also the alignment of the model itself. GPT-3.5, the brain of the ChatGPT, has the same model scale, but it's better aligned than GPT-3. And that's why it seems smarter. The OpenAI team fine-tuned the GPT model to make it more helpful in the context of chat assistant.
Let's discuss what exactly model alignment means:
Reasoning
The primary objective of language models is predicting texts. To predict texts, the model should be good at generating texts. One great thing about large language models like GPT is that they incorporate the mechanism of reasoning. Common sense reasoning is something we as human beings take for granted, but it's an entirely new thing for machines. But reasoning allows the GPT to become so good at simulating human behavior.
Reasoning is the use of natural language processing and machine learning techniques to analyze and understand text-based data. Think of reasoning as a logic that the model relies on when it answers the user's questions. Reasoning enables the model to "understand" the meaning of the text and use this understanding to provide the answer.
There are several different approaches to the reasoning for language models, including rule-based systems, knowledge graphs, and neural network-based models. GPT incorporates neural network-based models called transformers and gives the system the ability to learn complex relationships between words and handle large amounts of text corpora.
Reasoning also works for the prompt that the user submits to the system. The model generates the response in accordance with the prompt style. For example, if you submit a prompt that sounds like a quote from a scientific paper, the model will provide the output in a similar style.

But it's not enough to introduce reasoning into a model. It's also essential to fine-tune the model so it becomes better at following instructions. GPT uses semi-supervised learning—it combines unsupervised pre-training with supervised fine-tuning. Once OpenAI trains a model on a huge dataset in an unsupervised way, they fine-tuned the model to different tasks, using supervised training in smaller datasets. Codex, an AI system that translates natural language to code, is an excellent example of this approach.
Reinforcement learning
If you have experience working with GPT-3, you probably know this system was very sensitive to prompts. It was vital to articulate your intention properly so the system could understand what you wanted and generate relevant answers. GPT-3.5 is less sensitive to prompts because it was fine-tuned by people who evaluated the system's outputs. Think of fine-turning in this way—you show a few answers that the system generates for a particular question to humans and let them choose the best answer. It looks like a ranking system.
But you might wonder, “Okay, it's easy to do that for small data sets, but what about large datasets? How many human hours will it take?” The point is that reinforcement learning works a bit differently than a simple ranking system.
Reinforcement learning is a type of machine learning where the model learns to make decisions based on feedback it receives in the form of rewards. The goal of the model is to maximize its total reward over time. Reinforcement learning is a technique that summarizes human feedback and learns how to use it. The model that uses reinforcement learning tries to predict what answers the humans will react positively to. Since this model learns from humans in real-time, it becomes better and better at predicting. At the end of the training process, AI systems start to imitate humans.

Conclusion
The approach that OpenAI followed when creating GPT-3.5 clearly proves that "bigger is better" does not always work well regarding AI tools. GPT-3.5 has the same scale but is better aligned than its predecessor. Reasoning and Reinforcement learning allow OpenAI to align the GPT model in a way that can better understand user intention and generate more human responses.